
Introduction
A redundancy model associated with the service group defines how the service units in the group are used to provide service availability. This article provides a basic background into the types of redundancy that can be used in the OpenClovis SAFPlus Platform.
What is the redundancy model?
The redundancy models are based on the rules followed by the Availability Management Framework when assigning the active and standby HA state to service units of a service group for one or several service instances.
OpenClovis SAFplus Platform provides an SA Forum-compliant implementation of the 2N redundancy model, M+N redundancy model, and No redundancy model. Note that the N in the 2N model refers to the number of service groups, whereas N and M, when used in the other models, refer to service units. This is due to the common usage of the term 2N to refer to 1:1 active/standby redundancy configurations, which can be repeated N times.
1. 2N (or 1:1) Redundancy Model:
In a service group with the 2N redundancy model, at most one service unit will have the active HA state for all service instances (usually called the active service unit), and at most one service unit will have the standby HA state for all service instances (usually called the standby service unit). Some other service units may be considered spare service units for the service group, depending on the configuration. The components in the active service unit execute the service, while the components in the standby service unit are prepared to take over the active role if the active service unit fails. Active and standby components may reside either on the same node or on different nodes. Standbys for multiple actives can reside on the same node. Active and standby can share states using checkpointing (hot/warm standby).
Examples:
- Two Service Units with Spare SU on Different Nodes
![]()
This figure illustrates 2N Redundancy with Spare SU: A Spare SU is not activated or given a workload assignment when the Active SU and Standby SU are operational. However, if the Active or Standby SU fails, for instance, if the Node housing the Active SU becomes inoperational, the Standby SU is made Active and the Spare SU is promoted to Standby Role. If the failed SU is brought back into service, either automatically by the HA infrastructure or manually through the administrative interface, it assumes the Spare SU role.
- Two Service Units on the Same Node
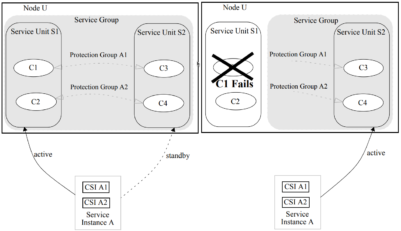
This figure illustrates 2N Redundancy for two SUs on the same Node: After a fault that disables component C1 within service unit S1, service unit S2 is assigned to be active for service instance A. Note that a fault affecting any component within a service unit that cannot be recovered by restarting the affected component, causes the entire service unit and all components within the service unit to be withdrawn from service. In this example, even though component C2 is still fully operational, it must fail over to component C4.
2. M+N Redundancy Model:
In a service group with the M+N redundancy model: the M standby service units can be freely associated with the N active service units. A service unit can be active for all SIs assigned to it or standby for all SIs assigned to it. In other words, a service unit cannot be active for some SIs and standby for some other SIs at the same time. At any given time, Some service units are active for some SIs, some service units are standby for some SIs, and possibly some other service units are considered spare service units for the service group. The variations of M+N supported and tested for by OpenClovis are N:1, N:N, and M:N, for instance, 3:1 ( 3 Active and 1 Standby), 3:2 (3 Active and 2 standby) 3:3 (3 Active and 3 Standby).
Examples:
- N:1 Redundancy Model
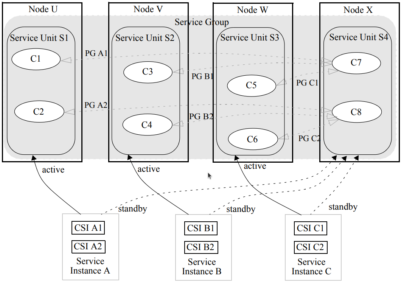
To illustrate what happens after a fail-over in the N+M model, assume that the service unit S2 fails. As a consequence, service unit S4 should be assigned the active HA state for SI B. Because, according to the redundancy model, S4 may not be assigned active for some SIs and standby for other SIs at the same time, the standby HA state for service instances A and C will be removed from S4.
- N:M Redundancy Model, Where N = 3 and M = 2
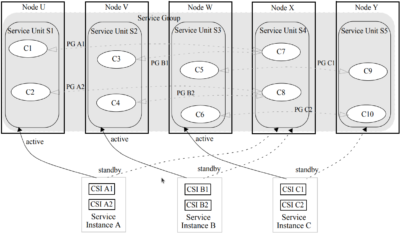
Assume that the service unit S2 and S3 fail. As a consequence, service unit S4 should be assigned the active HA state for SI B and service unit S5 should be assigned the active HA state for SI C. Because, according to the redundancy model, S4 may not be assigned active for some SIs and standby for other SIs at the same time, the standby HA state for service instances A will be removed from S4.
3. N Way Active redundancy model:
Active/Active: The N Way Active redundancy model of which Active/Active is a subset is not explicitly supported by OpenClovis SAFplus Platform, however, this can be achieved effectively in the following manner:
![]()
In the above figure is shown two SGs each identical in definition, but reversed in the order of Active and Standby SUs. When a SU is made Active it is assigned a Component Service Instance (CSI) which defines its work assignment, so that in this example each SU will be given 1/2 (or whatever fraction desired) of the total workload. In the above figure if Node 2 fails or the Active SU in Node 2 fails, then Node 1 takes on the entire workload.
4. No redundancy model:
In the No redundancy model, the service group contains one or more service units. This redundancy model is typically used with non-critical components when the failure of a component does not cause any severe impact on the overall system. A service unit is assigned the active HA state for at most one SI. In other words, no service unit will have more than one SI assigned to it. A service unit is never assigned the standby HA state for an SI. The AMF can recover from a fault only by restarting a service unit, or as an escalation, by restarting the node containing the service unit.
Example:
- No Redundancy Model
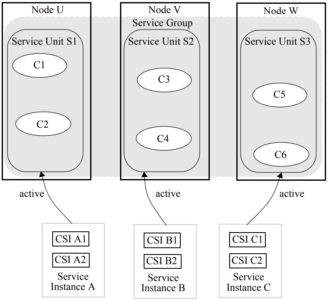
Assume that the service unit S2 fails. It doesn’t affect service unit S1 and S3. Service unit S2 is recovered only by restarting the service unit S2 or by restarting the Node V.
Conclusion
By leveraging OpenClovis’ tested and supported redundancy models, system designers and developers can focus on their core application goals without worrying about the cost and complexity of ensuring system reliability and availability. If you need any assistance with redundancy models.
Other support, please send email to support@openclovis.org.